Graph Processing
本文主要简单介绍一些主流的图处理算法
(一)、基础知识
1、图的切分方式
图的切分方式可以分为两种:
- Edge-cut 边分割
- Vertex-cut 顶点分割
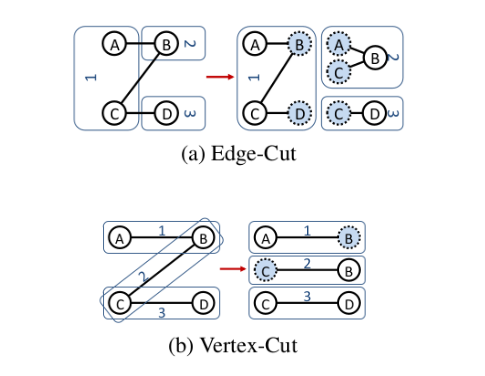
1.1、Edge-cut
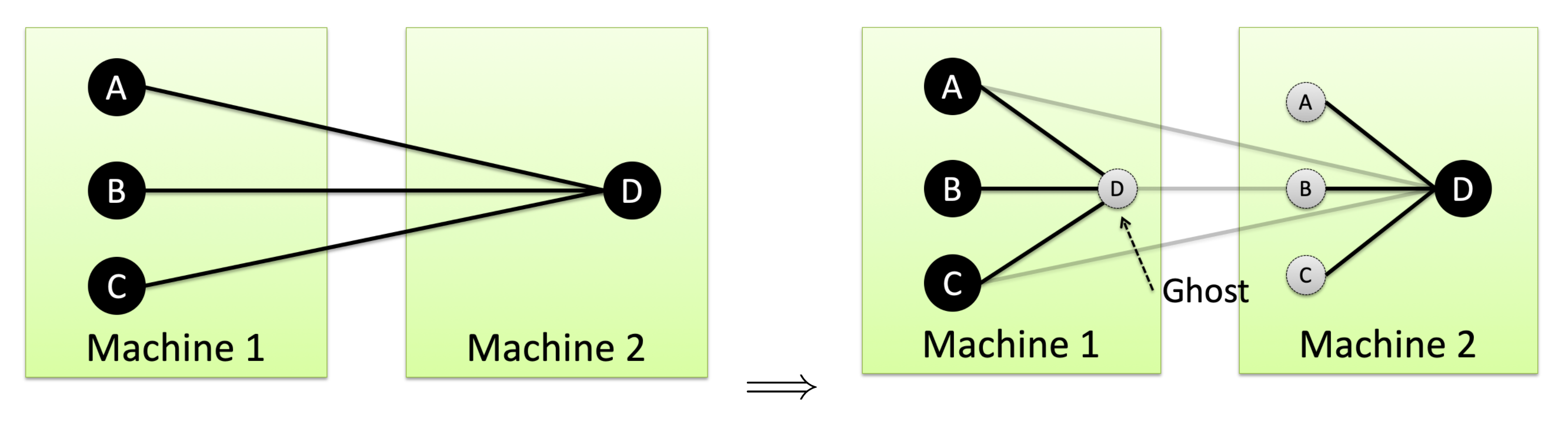
边分割的话,会把各个点分到不同的机器上,当遇到两个机器上的点有边时,则把边切开,并在两个机器上生成ghost虚拟顶点;如下图所示:
该方法的缺点是:
- 被分割的边,在各个机器上都有一份边,造成边的数量剧增。当边的数量本来就多的话,造成的overhead更大。
- 当 master 节点发生更改时,需要同步给其 ghost 节点,造成网络开销。
目前两种流行的图处理框架:GraphLab 和 Pregel 用的都是Edge-cut。保证节点均匀的分布在整个集群中间,边被切分成双份分散在整个集群中间。
1.2、Vertex-cut
引入 Vertex-cut 的目的:
- 减少通信开销
- 权衡图计算和图存储开销
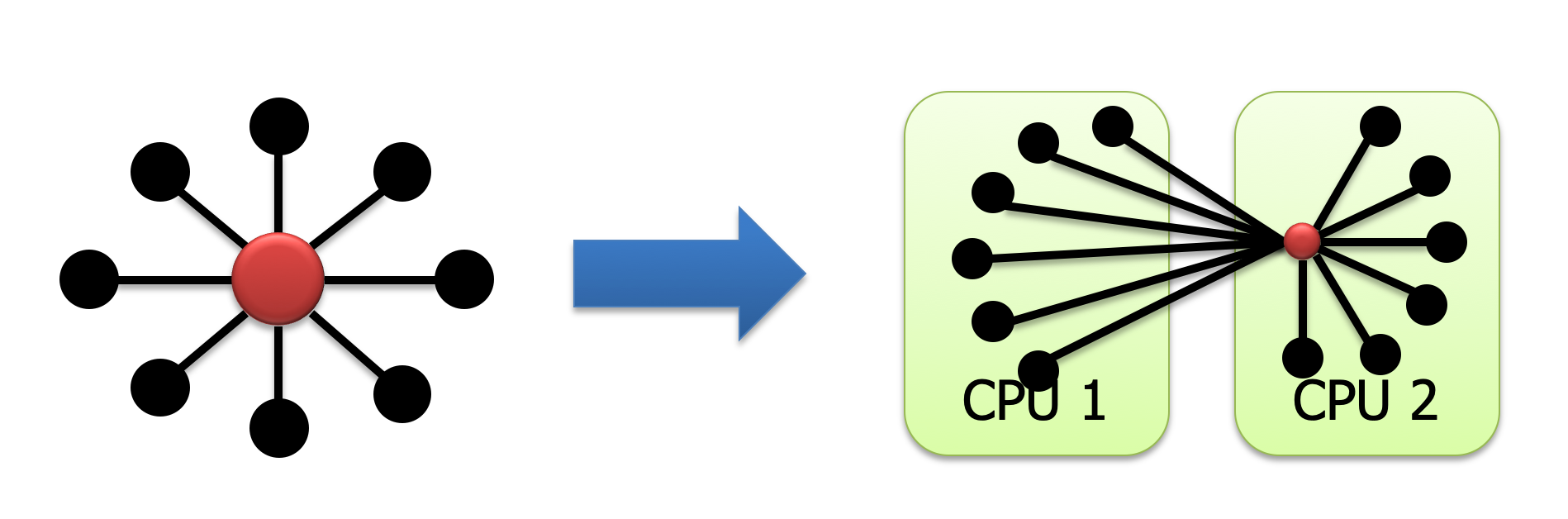
对于边的数量很多的节点,如果使用 Edge-cut 的话,会使得相应的被切割的边数量变多;且该点对应的 ghost 顶点也很多,所以当需要通信的话,造成的通信开销也变大。
所以提出了Vertex-cut:
把 High-degree 的顶点进行顶点分割。
这样做的好处是:
- 图中的
边的总数量不变 - 边被均匀的分布到不同的机器上
目前两种流行的图处理框架:PowerGraph 和 GraphX 用的都是Vertex-cut。
2、同步计算和异步计算
2.1 同步计算
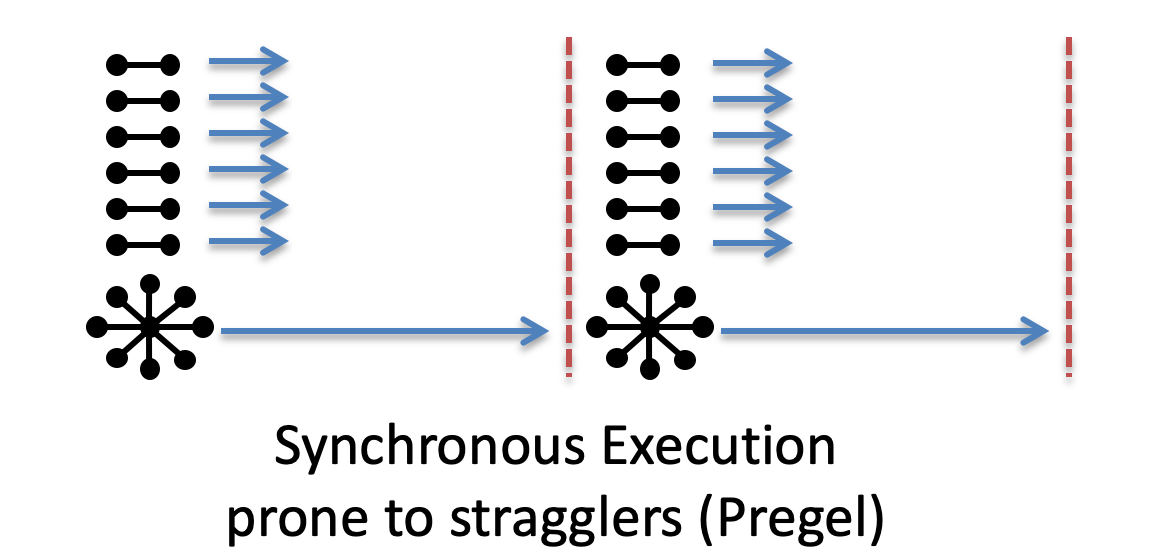
当所有顶点都计算完之后,才能开始下一轮迭代计算。
缺点:存在 Stragglers(木桶的短板效应);当某个顶点计算很慢时,所有别的顶点需要去等待它。
目前: Pregel 用的就是同步计算的方式。
2.2 异步计算
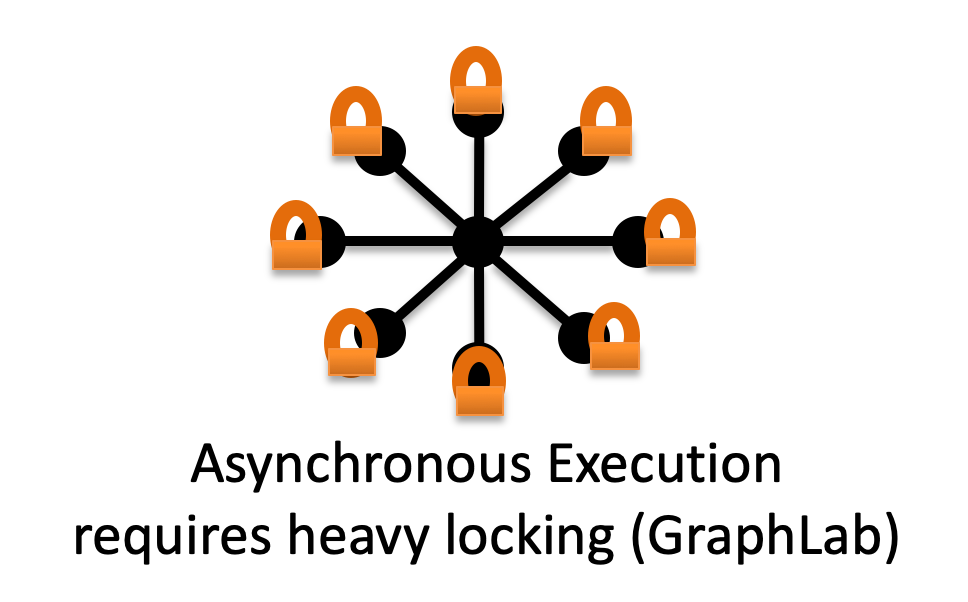
异步计算允许一些不造成冲突的顶点同时去更新。不是等所有顶点都完成了一次迭代之后才开始下一轮迭代;而是,只要不冲突的顶点就可以继续执行下去。
缺点:为了避免冲突,需要使用锁;而大量的锁会引起性能下降。
(一)、Pregel
该算法是 Google 2010 年提出的图计算的算法。
对图进行edge-cut;是一种同步计算的方法。
该算法以Bulk Synchronous Parallel(BSP) 整体同步并行计算模型 为计算模型;
在分布式下面,使用message-passing(消息传递)在各个顶点之间传递消息;并且是shared-nothing,也就是说对某个顶点的计算,其所需要的资源都在该顶点所在的机器上面。
编程思想是:Think like a vertex:每一个顶点去跑一个算法,然后并行的去在不同的顶点上运行算法。
计算步骤:
- 收取邻接顶点发来的 messages
- 执行该点上的算法
- 更新该点的值
- 发出 message 给邻接点,激活邻接点重新计算
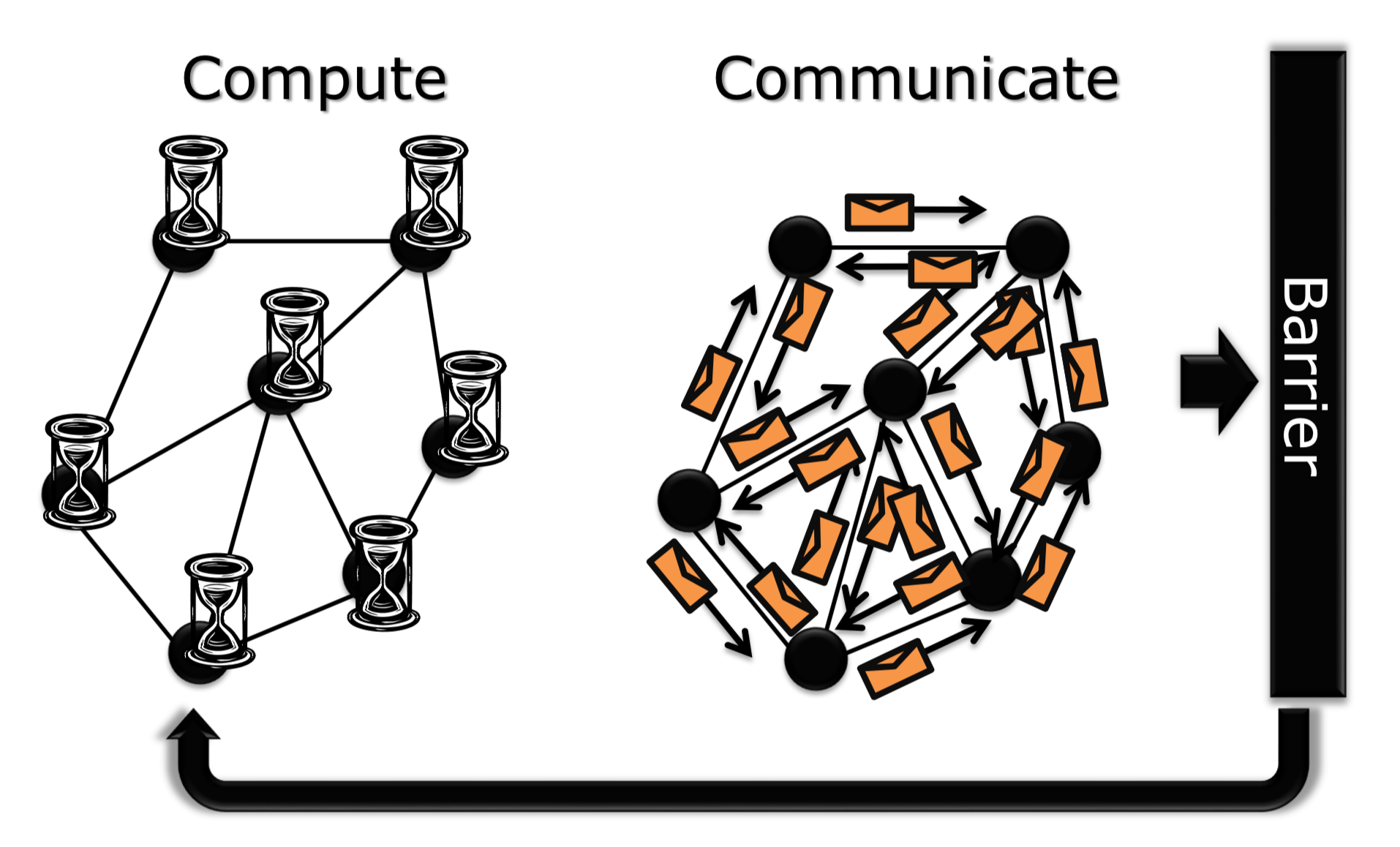
思路:把计算和通信分离;当所有顶点计算完之后,再统一进行消息传递;消息传递完之后,再统一下一次迭代的重新计算。直到收敛或者迭代到一定数量,也就是同步计算。
(二)、GraphLab
思路:认为 Pregel 这种同步计算的方式太慢,特别是对于稀疏图的计算,每次迭代中计算的点的数量很少,且存在木桶短板效应。
所以主要思想是:提出异步计算的方法。
首先,也需要把图进行划分,划分到不同的机器上;使用的划分方式是:Edge-cut。
当要更新某个顶点时,主动(pull)的向邻接顶点获取信息。注意这里和 Pregel 的区别,Pregel 使用的被动(push)的从邻接顶点收取消息。
那么主动和被动有什么本质的区别吗?
有,当主动 pull 的话,此时的邻接顶点可以是在 Inactive(空闲) 状态,也就是可以睡觉;而 push 模式的话,邻接顶点必须是 active 状态给你发送消息。
计算步骤:
- 从邻接顶点获取信息
- 更细顶点数据
- 如果需要,去叫醒邻接顶点开始计算
在这个算法中,并不是所有顶点同时收敛;而是动态的有些顶点先收敛,之后其他顶点开始慢慢收敛。
那么,如何异步调度哪些顶点开始计算呢?
- Round Robin
- FIFO
- Priority
异步计算的缺点:当相邻两个顶点同时计算的话,会发生冲突,你拿邻接点开始计算,邻接点也拿你的数据开始计算,所以会造成 consistency 问题。
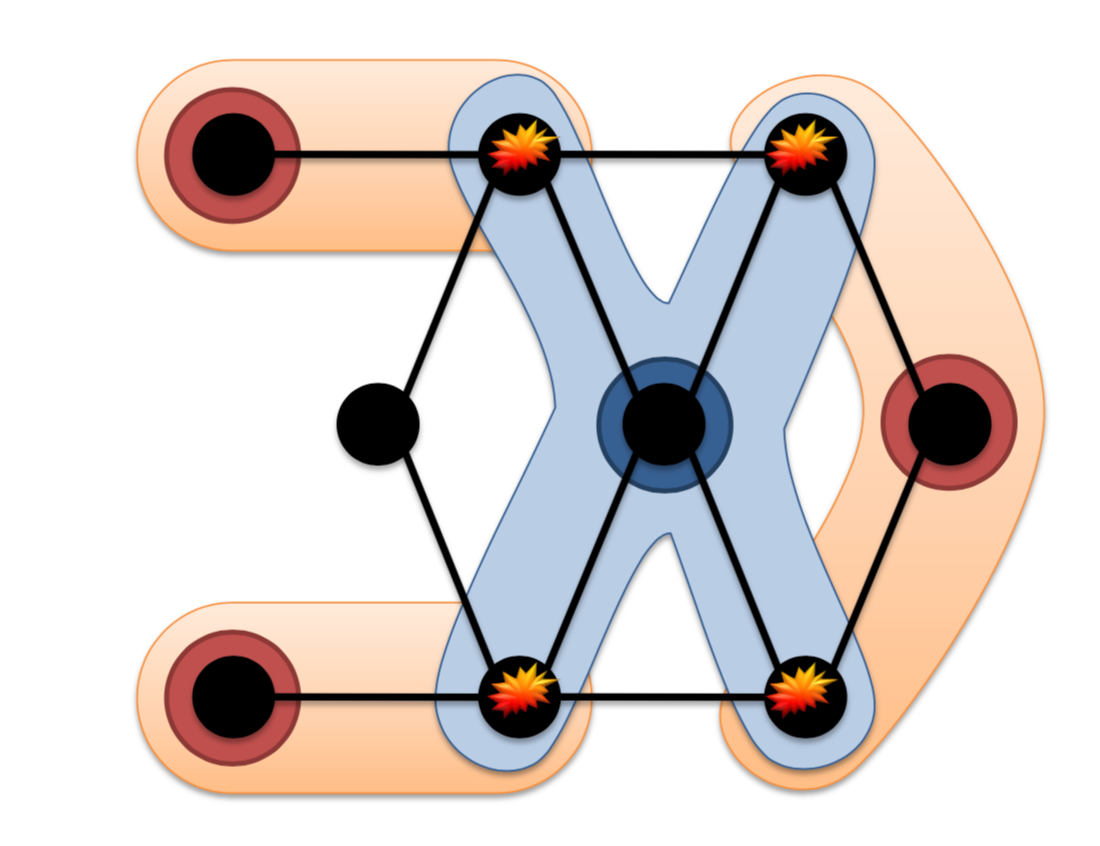
简而言之:用锁
(三)、PowerGraph
主要想法:对于 Pregel 和 GraphLab 都是基于Local(本地计算),也就是当计算某个顶点的时候,其所需要的所有信息都在该本地机器上。但是,由于为了达到本地计算,会在每条分割边上产生一个 ghost 顶点;且这些 ghost 顶点之间需要同步。当某个顶点的边的数量很多时,产生的ghost也变多(每分割一条边就会产生一个ghost);所以当这个顶点更新时,需要通知所有的ghost,该操作会带来很大性能开销。
造成以上问题的主要原因:使用edge-cut。
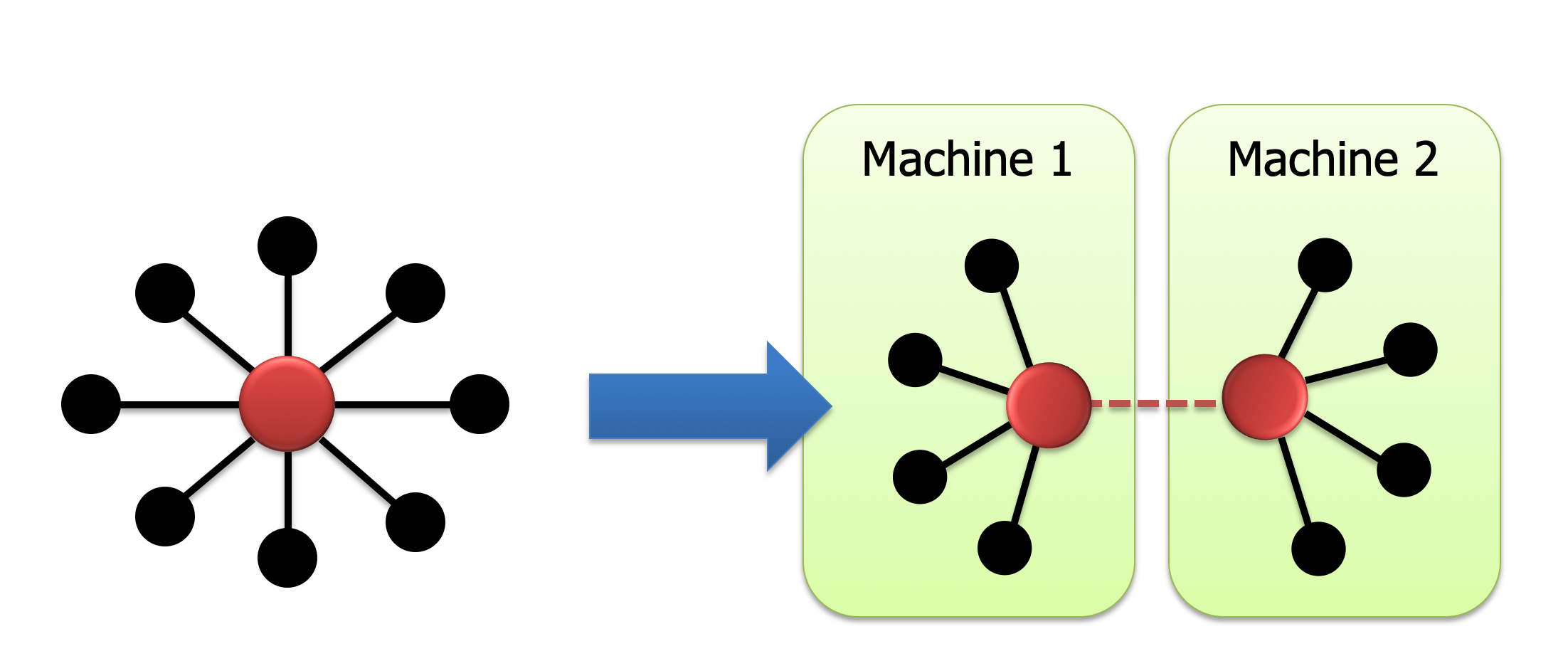
PowerGraph 思路:采用 vertex-cut:
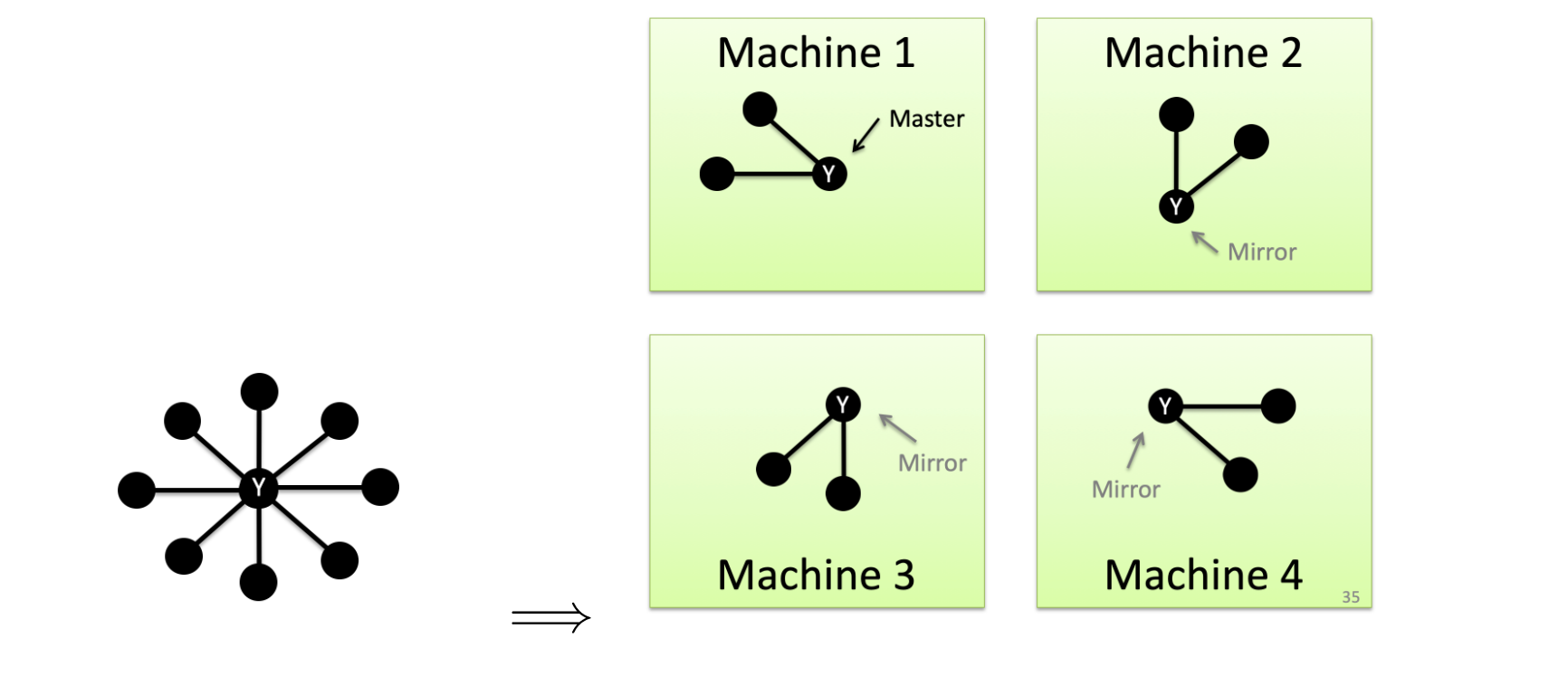
然后,计算的时候:
- 每个机器
并行地计算自己的本地sum - 最后整合到 master 主机上
- master 主机更新数值之后,同步给告诉 mirror 节点
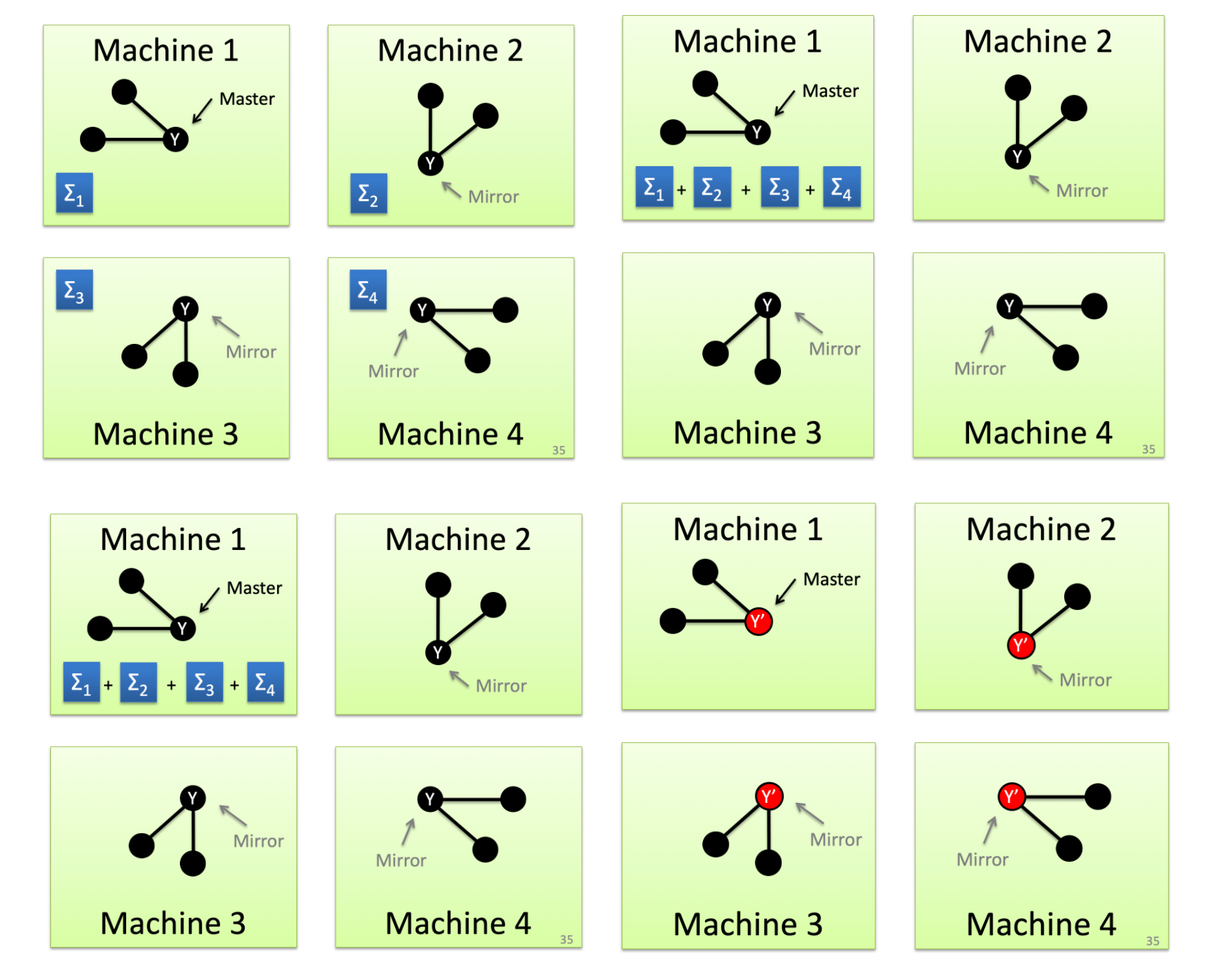
由于 PowerGraph 只要同步一个点的节点信息,所以可以减少通信信息。同时对于边的数量非常大的顶点,可以把对于该顶点的计算并行到很多机器上运行。从而可以提高并行度。
(四)、PowerLyra
主要想法:由于之前的工作都是使用:one size fits all 的想法;要不都是使用 vertex-cut 要不都使用 edge-cut。 这样做会带来问题:
- 当边的数量很多,但是使用 edge-cut 的话:
- 很大的竞争
- 很大的通信开销
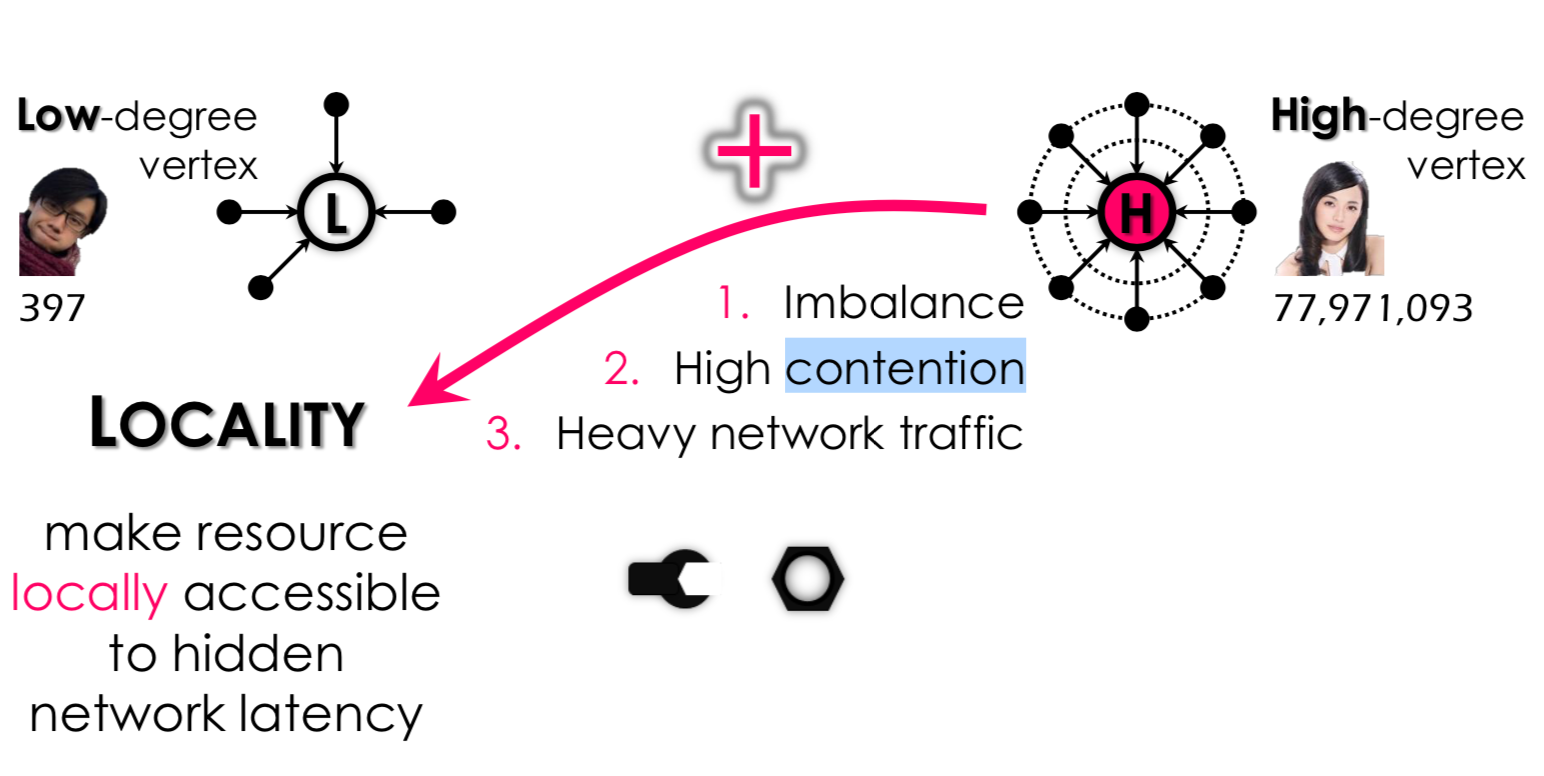
- 当边的数量很少,但是使用 vertex-cut 的话:
- 没必要的同步操作;因为把一个顶点的计算,分布到多个机器上计算,然后整合。
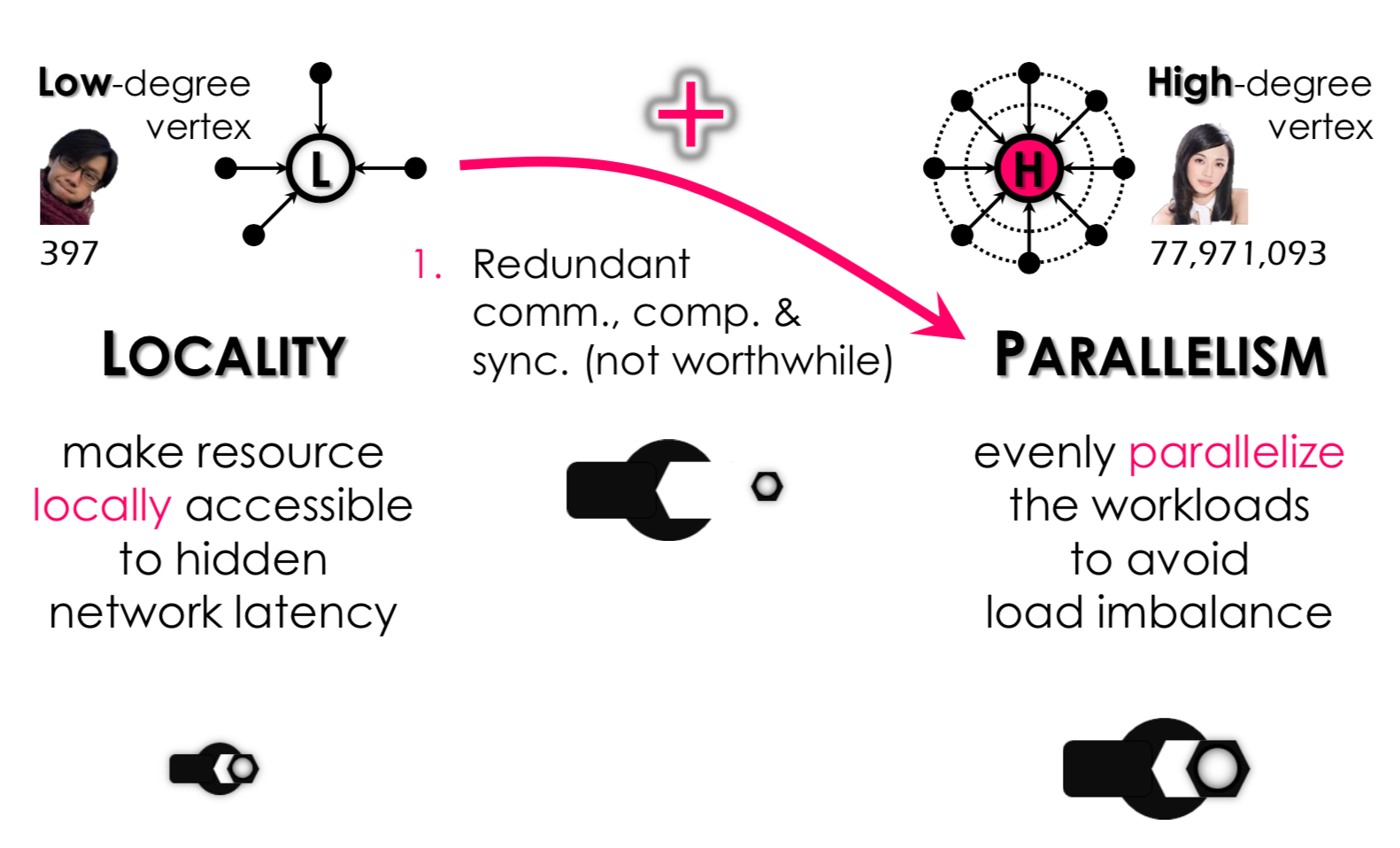
主要思路:对于不同的顶点,动态采用不同的图分割方式和计算方式。
- 对于边数很多的顶点,采用类似 vertex-cut 的切分方式
- 对于边数很少的顶点,采用类似 edge-cut 的切分方式
(五)、GraphChi
单机下的图计算。
对于一个很大的图一般是在内存中存不下的;所以一般都是存储在 disk 上,但是存储在 disk 上的话,会带来一些问题。比如读取数据的时候是 Random Access 的,所以读取数据很慢。
想法: 如何更改图的数据结构,使得读取数据的时候能够达到好的性能,也就是相关的数据尽量在一起。
做法:
- 把图分割成很多 sharded,使得每个 shared 能够一次性被加载到内存中
- 边的终节点相同的顶点分配到同一个 shared 中
- 对于每个shared中,按照初边序号进行排序
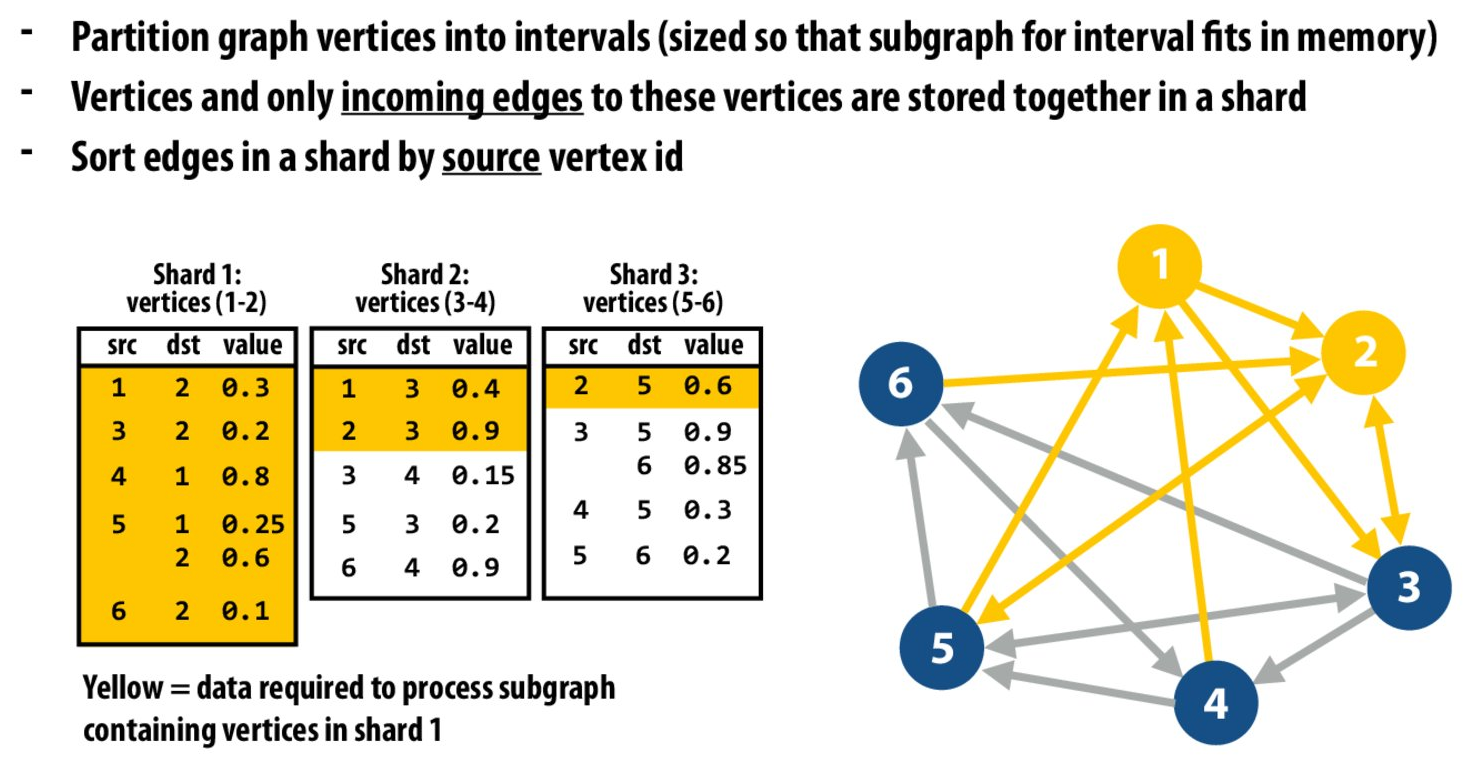
按照以上划分的话:当我需要读取与顶点1和顶点2有关的数据的话,只要把 shard 1 中的顶点全部读取,然后看其余的shard,找到src为1或2的信息;由于每个shard中按照 src 排序了,所以每个 shard 中需要读取的数据都在一起,减少 Random Access 的开销。
对读取与顶点1和顶点2有关的数据的话,只要读取以上黄色的区域就可以了。