MapReduce
本文简单介绍分布式计算框架 MapReduce
(一)、引入
MapReduce 的设计灵感来源于 Python 中的 $map$ 和 $reduce$ 函数。首先来看一下这两个函数是什么样的:
$map$ : 接收一个函数 $f$ 和 一个数组 $list$ (或者可以 iterate 的一串数据) , 然后把该函数运用在该数组中的每个元素(element)
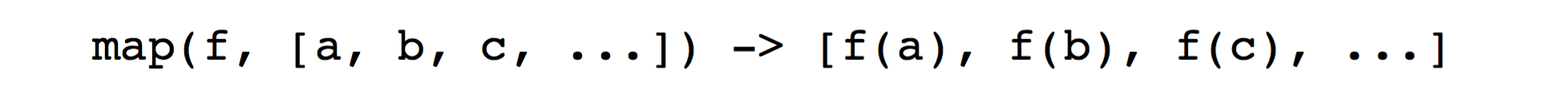
$reduce$:接收一个函数 $g$ 和 一个数组 $list$ ;然后对该 list 中的前两个元素运行函数 $g$ ,生成的结果当成 list 的一个元素,然后递归取前两个元素再次运行函数 $g$ 。
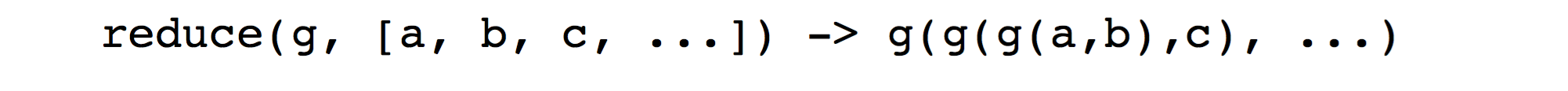
实例:
问题:给定一个数组,求该数组中每个元素都平方,然后相加的结果。

所以以上的执行过程可以看成:
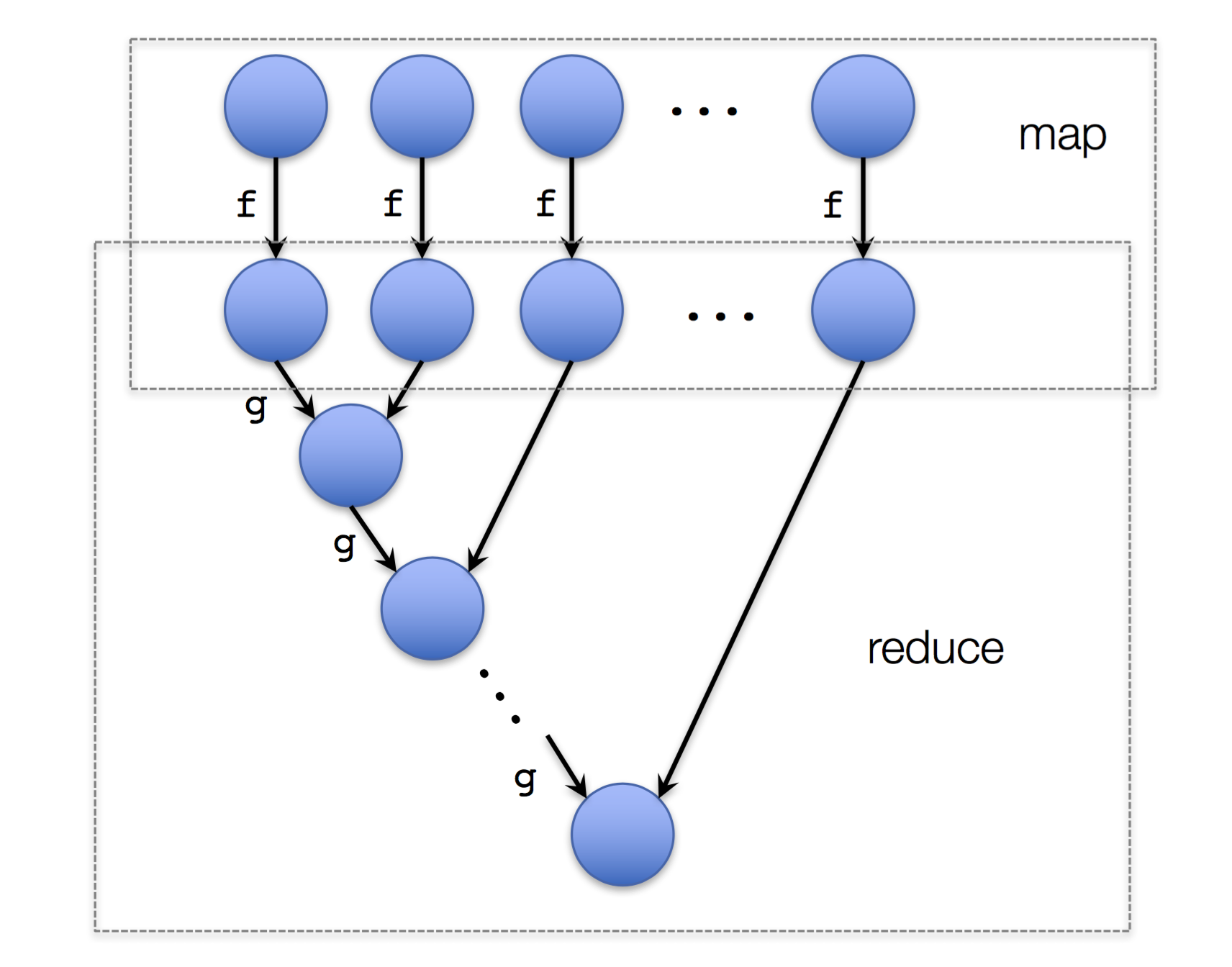
mapper:就是传给 $map$ 函数的处理函数;如以上例子的 $f$。 reducer:就是传给 $reduce$ 函数的处理函数;如以上例子的 $g$。
关键就在于程序员只需要去实现:$maper$ 和 $reducer$ 函数。
(二)、MapReduce
可以把 MapReduce 看成是 $map+reduce$ by key
- $mapper$ 函数并不是返回一个 value,而是返回一个 key-value 对(可能很多有相同的 key )
- 在调用 $reducer$ 函数之前,需要把所有 key 值相同的结果存到一起。
2.1 过程
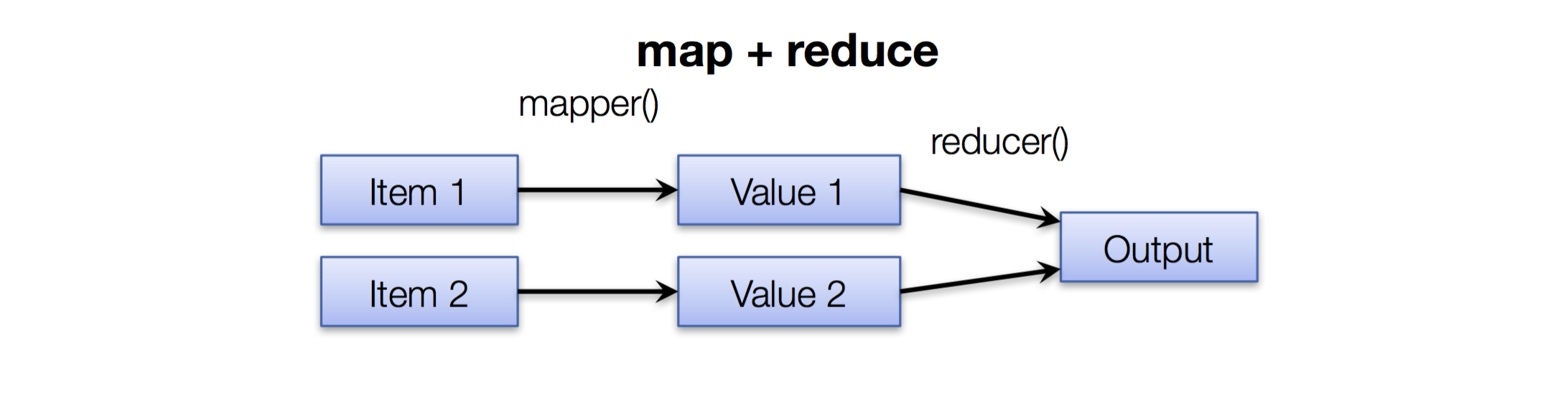
对于普通的 map+reduce 的过程如图所示:
给定 item ,通过 mapper 函数得到新的 value,然后再通过 reducer 函数得到最终结果。
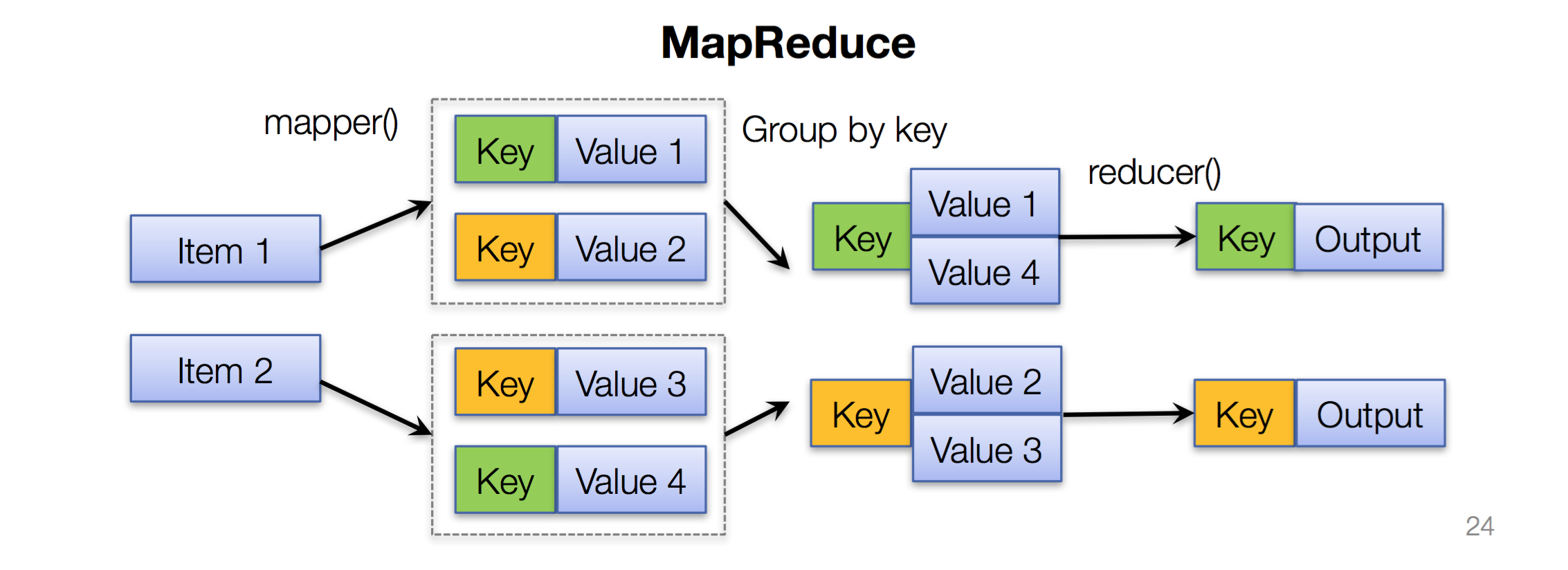
而对于 $MapReduce$ 的过程为:
-
给定输入 items ;通过 mapper 函数最终得到 key-value pair
-
execution engine 会把所有相同的 key 归类到一起。也就是 Shuffle过程(并不是程序员来完成)
-
最后 reducer 会根据 key 来完成整合,最后得到 key-value 对。(每一种 key 用一次 reducer 函数;当然,每个 reduce worker 可以处理多个 key)
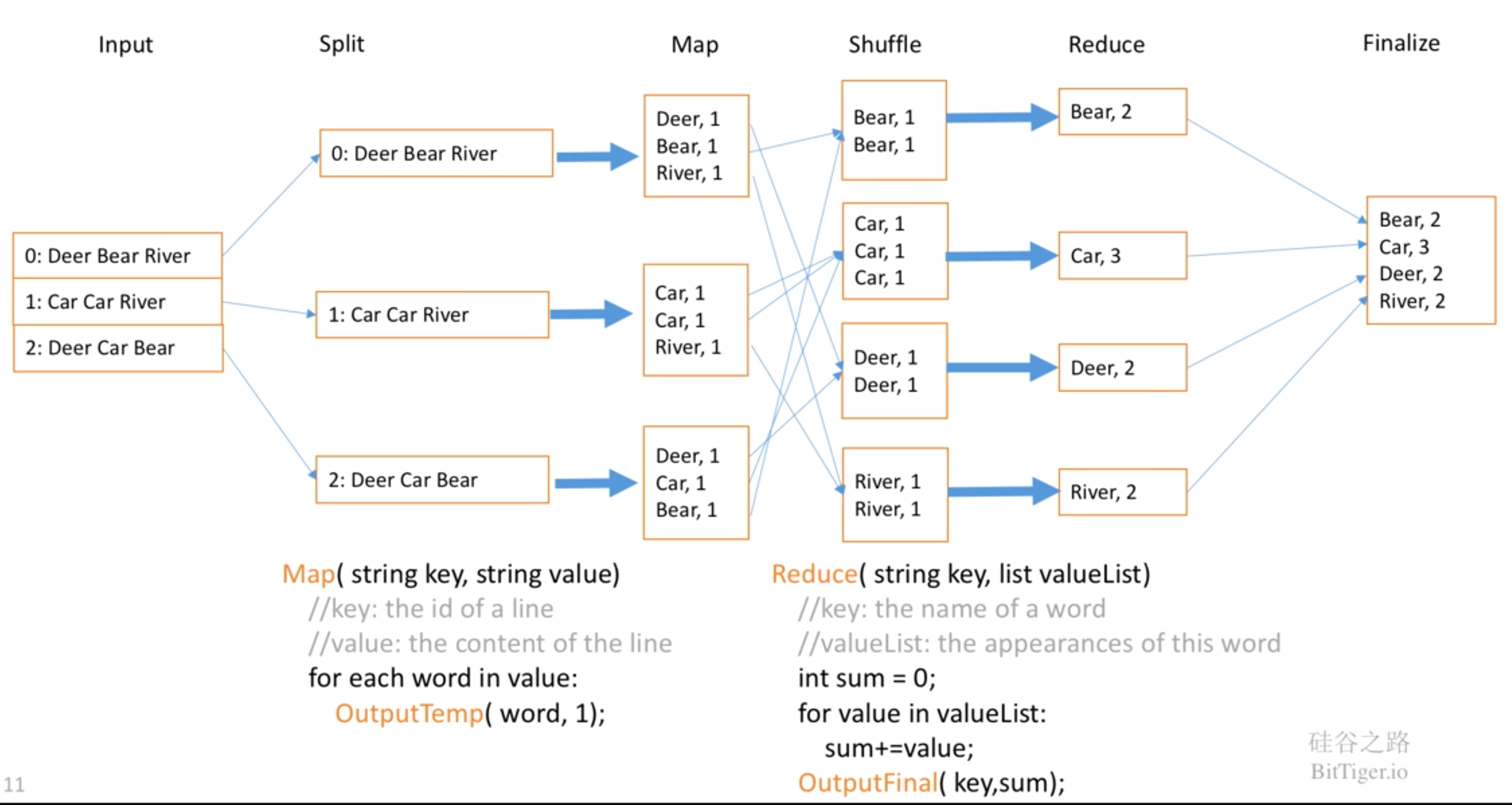
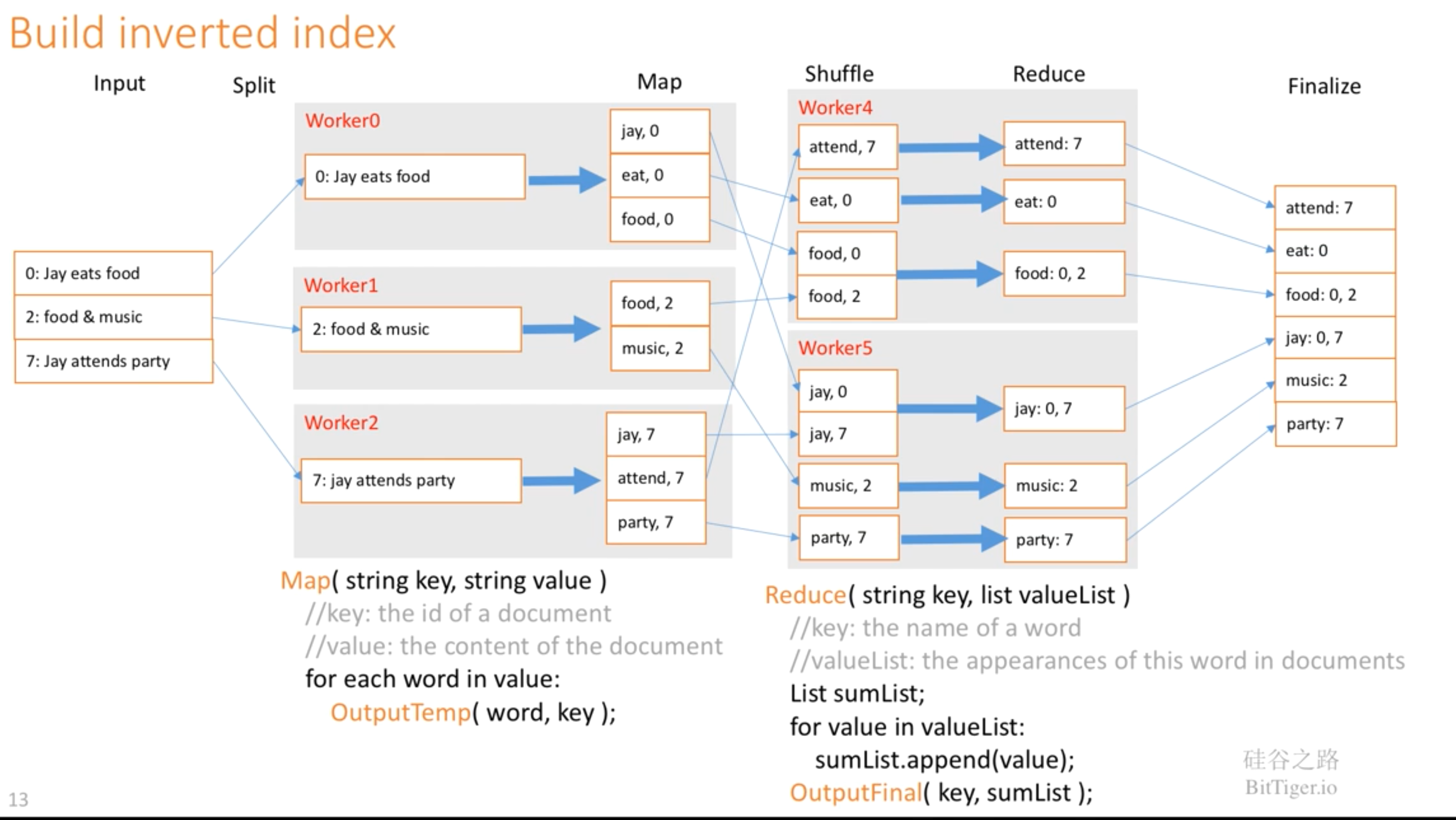
2.2 实例

(三)、MapReduce 系统架构
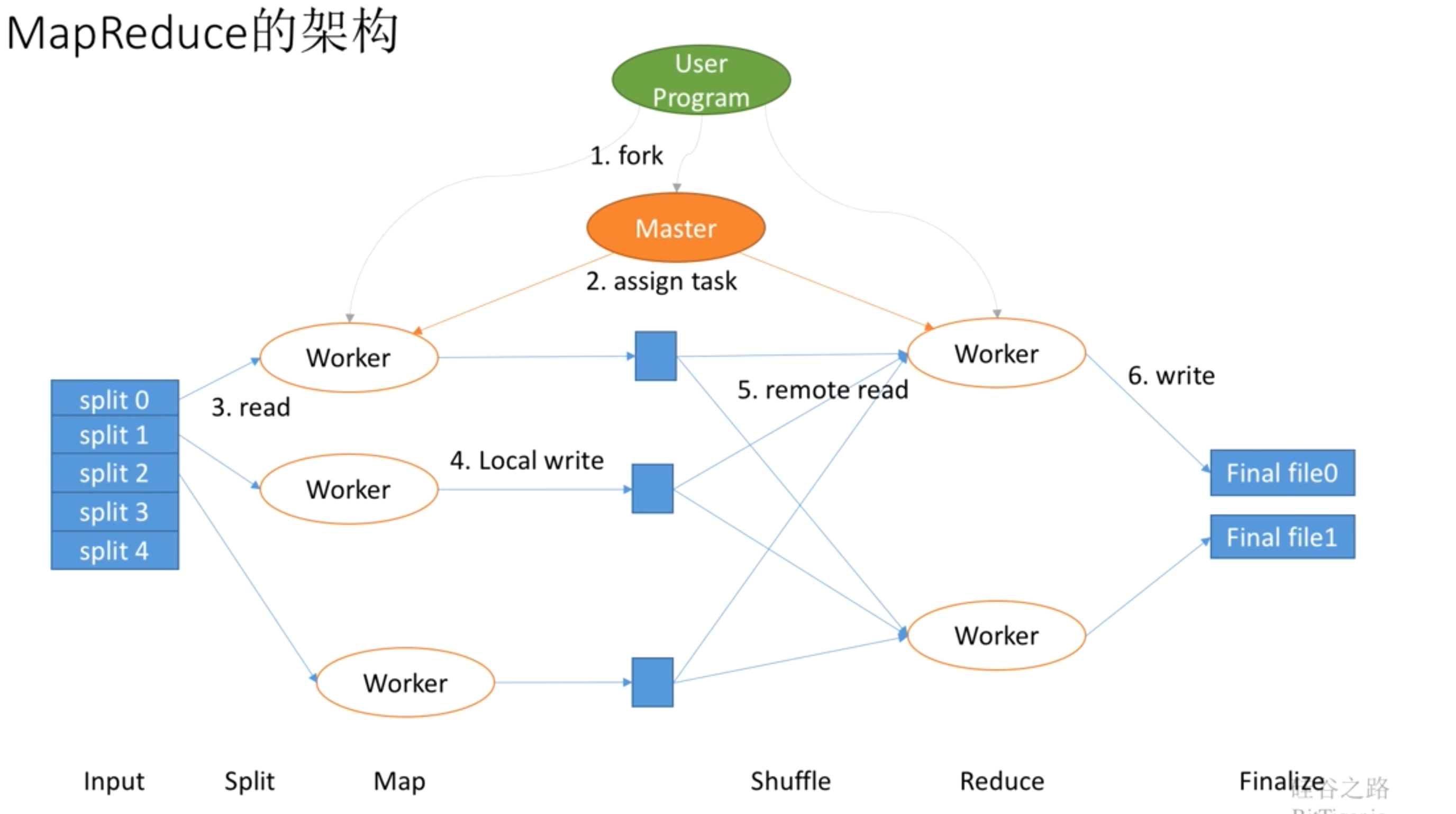
- 首先,我们有个用户进程来协调程序如何运行。如它会根据数据规模来判断需要把任务拆分给多少个 mapper 和 reducer 去完成。 当它认为需要 5 个 mapper 去完成时,就会把数据拆成 5 份。
-
接着产生很多 woker (map woker 和 reduce woker);而且还会产生一个 master worker,这个 $master$ 会作为用户的代理来协调整个过程,这样的话用户就可以去做别的事了。
- $master$ 就会告诉 worker 去拿相应的数据(也就是分配数据的过程)。
- map worker 就会本地完成 map 操作。
- 当 map 完成之后,$master$ 就会通知 reduce worker 去拿数据。
- $reducer$ 完成 reduce 操作
- 最后把结果写到最终的文件中。
所以总结为:
- split : 数据切分,分给不同的 map worker。(map worker 去拿数据)
- map : map worker 本地调用 mapper 函数
- Shuffle : 把数据分配给不同的 reduce worker (相同的 key 的数据给同一个 reduce worker)
- reduce :reducer 完成 reduce 操作
- finalize :数据整合
(四)、MapReduce 完整过程
Step1 :split input files into chunks (shards)
- 切分数据成成很多 shard
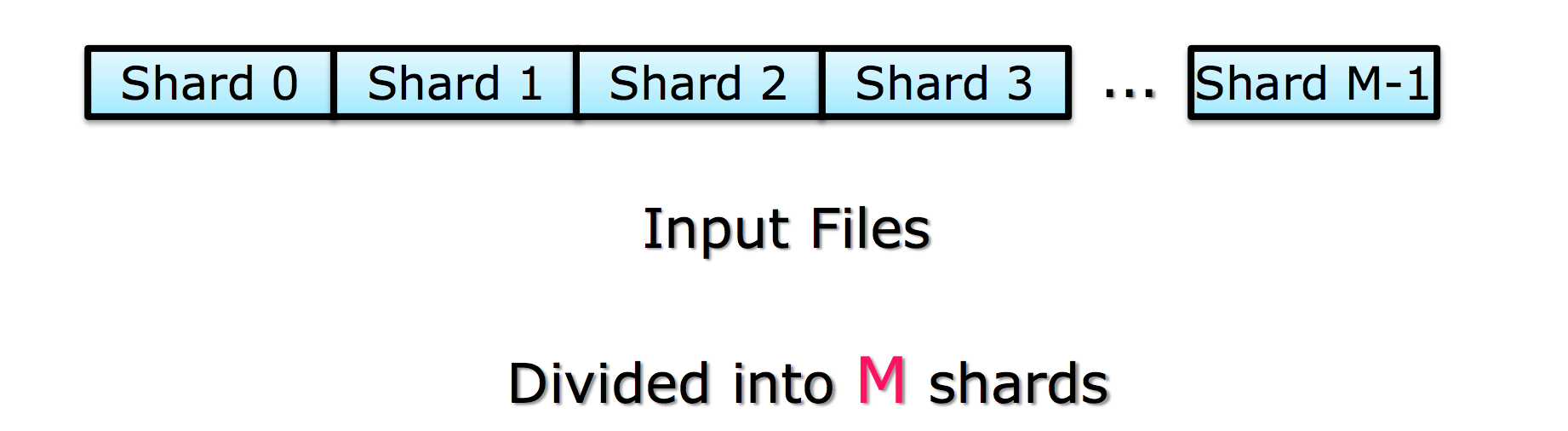
注意: $\color{blue}{shards 的数量 M» worker 的数量}$
原因:对于每个 worker 输入大小一样时并不能保证执行 shard 的时间一样(各个机器的执行速度并不一样);所以说每个 worker 分配一个 shard 并不合理。而当 $M» worker 的数量$ 时,我们可以动态分配,哪些 worker 完成任务了就来取数据执行,这样做更加 balance 。
Step 2 :fork processes
生成很多 wokers 和 master
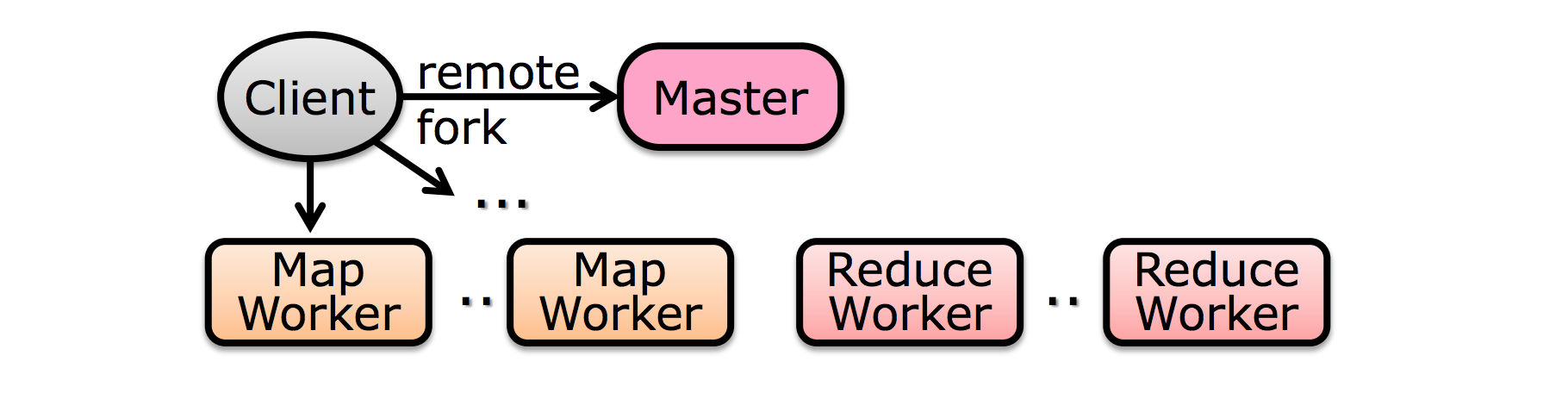
Step 3 :map task
-
从输入中读取 shard
-
根据输入数据生成 key-value pair;最终结果存在 memory 中

Step 4 :create intermediate files
- 把生成的 intermediate files 定期的写入到 disk 中
- 当完成后需要通知 master
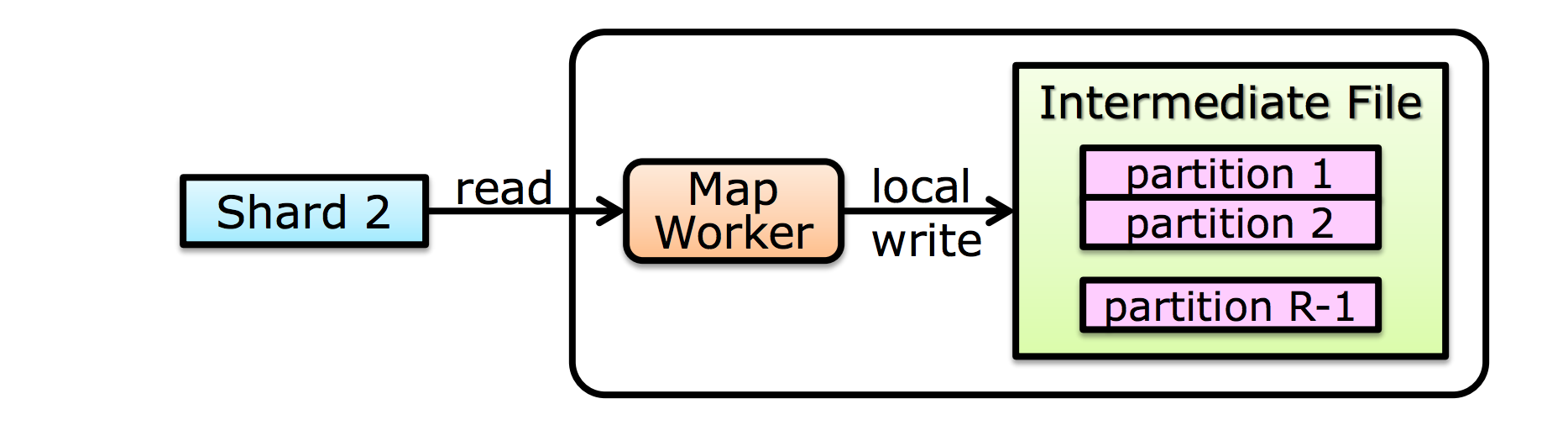
Step 4a :partitioning
-
根据 key 进行排序
-
Partition function : 根据 key 值来决定分配给哪个 reduce worker
- 默认函数为:$\text{hash(key) mod M}$
-
每个 reduce worker 会从 所有 map worker 中读取属于它的 partition。
Step 5 :sorting intermediate data
- 可以通过 master 知道数据位置
- 通过 RPC 从 map workers 的 local disk 读取数据
- 根据 key 值排序
- 所有相同的 key 会 group 到一起
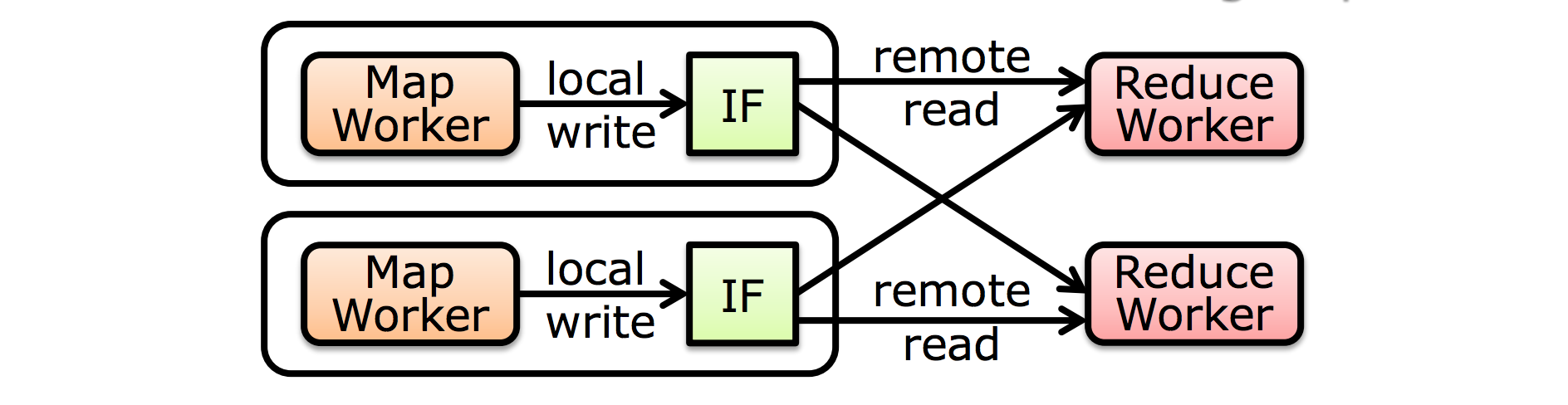
$\color{red}{相同的key一定去同一个reducer}$
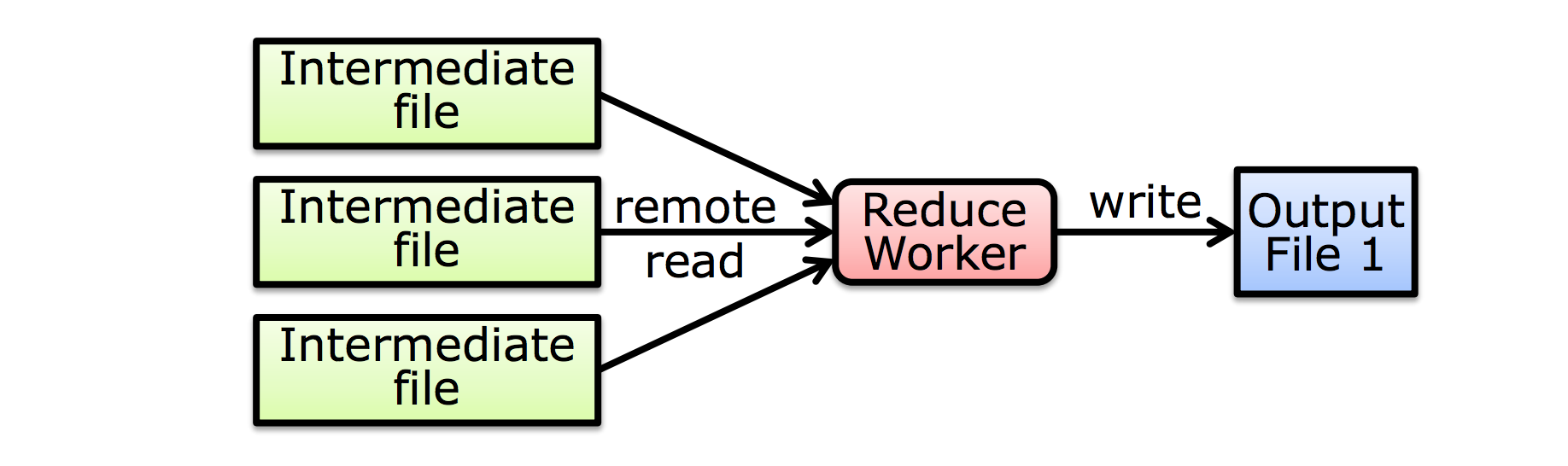
Step 6 :reduce task
- 根据 key 和与之对应的一系列 values 整合结果
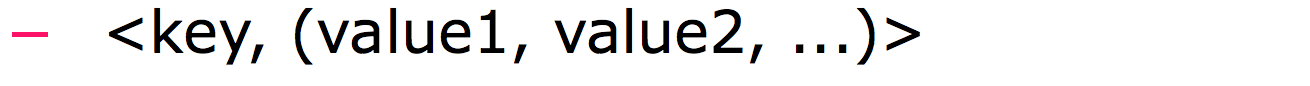
- 最终结果 append 到输出文件
Step 7 :return to user
(五)、MapReduce 设计细节
3.1 Locality
- 输入文件(input)和输出文件(output)保存在 GFS 中。
- MapReduce 运行在 GFS 的 chunkservers 上面;
- 主要是为了让计算和存储在相同的机器上
- Master 调度的时候尽量让含有相应数据的 worker 处理对应的数据
3.2 Fault Tolerance
- Master 周期性的去 $ping$ 每个 worker (检查 worker fail)
- 如果一定时间内 worker 没有回复,则标记该 worker failed
- 把分配给该 worker 的任务重新分配给别的 worker (re-execution)
- Master failure (Master fail 的情况)
- 状态 checkpointed to GFS
- 由 GFS 来恢复 Master 并继续执行
3.3 Straggler
问题:有的 worker 执行速度快,有的 worker 执行速度慢(straggler);而这些速度慢的 worker 会使得整个计算时间变慢。
解决方案:把任务分配给别的 worker,谁先做完就使用谁的结果。
3.4 Intermediate key-value pairs
问题:中间结果表示 intermediate key-value 存储在哪里?存在 mapper 的本地磁盘还是 reducer 的本地磁盘。
第一种方案: Mapper-side:
- 发送数据前做 partition;可以减少网络传输
- 如果 Map task failure ; 会造成部分数据丢失
- 如果 Reduce task failure; 只需要重新发送数据
第二种方案: Reducer-side:
- Pipeline -> overlap the transfer time
也就是说发送数据和执行可以 overlap (有的做完一部分 Map 后就可以发送数据,并不需要等待所有 Map worker 都做完后发送)
目前普遍用的是第一种方案。